
The above image was generated using Source: DALLE-3 on 16/03/2025 using prompt “Generate an image highlighting “Multimodal Chain-of-Thought LLM’s ”
What Is Chain-of-Thought Prompting?
Imagine solving a math problem or logic puzzle by writing out each step of your thinking process. Large language models (LLMs) can do something similar! Chain-of-thought (CoT) prompting is a technique where we encourage the model to generate intermediate reasoning steps before finalizing an answer
In other words, the model “thinks out loud” – it might list facts, perform calculations, or logically work through the question step-by-step, and then use that reasoning to produce the answer. This approach often leads to better accuracy on complex problems because the model isn’t trying to jump directly to the answer; it’s iteratively working it out, much like we would.
CoT prompting can be done explicitly by adding cues in the prompt. For example, you might append a phrase like “Let’s think step by step” to your question. This signals the model to spill its thought process. Researchers have found that with the right prompts or fine-tuning, even very large models can produce impressive multi-step reasoning – solving math word problems, answering tricky commonsense questions, and more – all by breaking them down into chains of smaller thoughts.
Why is this useful? For one, it makes the model’s reasoning transparent. You can see why it arrived at a given answer, not just what the answer is. Additionally, the process of generating a reasoning chain can help the model avoid mistakes. If a step in the chain is wrong, ideally it might correct itself in the subsequent steps (though this isn’t guaranteed). Overall, chain-of-thought has become a powerful prompt technique for tackling tasks that benefit from logical decomposition and intermediate calculations.
Extending CoT to Multiple Modalities
Chain-of-thought so far has mostly lived in the land of text. But humans don’t solely rely on text – we use images, diagrams, and other modalities to interpret and understand information. Wouldn’t it be great if AI could do the same? Multimodal Chain-of-Thought (Multimodal-CoT) is the idea of combining vision (images) and language (text) so that a model can reason step-by-step with information from both.
In Multimodal-CoT, a question might include an image (or some visual context) along with text. The model’s chain-of-thought should then incorporate clues from the image and the text together. For example, if the question is about a chart or a diagram, a purely text-based model might struggle or hallucinate details. A multimodal model can actually look at the chart image, extract the relevant details (like a particular trend or label), and include that in its reasoning steps, leading to a more grounded answer.
To make this work, researchers Zhang et al. (2024) propose a two-stage framework that separates the reasoning from the answering. First, the model focuses on generating a rationale (the chain-of-thought) based on both the text and the image. Second, it uses that rationale to infer the final answer. By splitting these tasks, the model can produce a better thought-out explanation before committing to an answer. This is like having the model be a teacher: first it writes down its “workings” (stage 1), then it gives the conclusion
Why go through this trouble? Smaller models have fewer parameters and thus less capacity to capture intricate reasoning steps, making chain-of-thought generation inherently more error-prone. Integrating visual information compounds this complexity. However, following a two-step approach—first generating a rationale, then using it to infer the answer—helps mitigate these limitations and yields more stable, accurate reasoning.
One big reason to add images to the mix is to reduce hallucinations – the model’s tendency to make stuff up. If a language model is unsure, it might just fill in gaps with plausible-sounding but incorrect assumptions. With an image, the model has actual evidence to consult, making it less likely to invent facts that aren’t there. In the words of the paper, Multimodal-CoT “offers the advantages of mitigating hallucination and enhancing convergence speed. Essentially, the visual input serves as an anchor to reality for the model’s thoughts.
Example: Reasoning with an Image(Bar-Graph)
We will use a bar chart that illustrates a hypothetical city’s population over few years and we’ll walk through a simplified question, first with text-only input, then with approximate “vision” input in the form of a chart description.
Scenario Setup
- Question: “Which year had the largest population increase compared to the previous year?”
- Context (Text): “The bar chart below shows the population in thousands for each year from 2020 to 2023 in City X.”
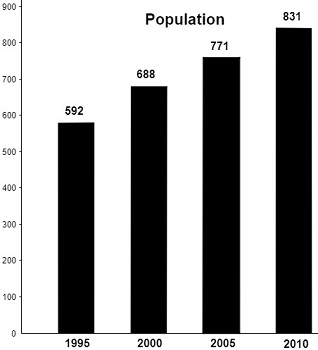
- Bar Chart (Image): Suppose it looks like this:
1) Text Only Prompt
Since this blog is more targeted towards smaller models, we are using LLAMA 3.2 with 3B parameters to test the below demo
User Prompt:
Question: Which year had the largest population increase compared to the previous year?
Context: The bar chart shows population figures for 1995 to 2010 in City X.
Let’s think step by step.

When our model is asked to identify the largest population increase from a bar chart—but isn’t actually given the bar chat—it invents plausible figures, listing out year-by-year values that don’t exist in the prompt. This is a textbook case of hallucination: the model is filling information gaps with made-up details rather than admitting uncertainty. It illustrates why truly multimodal reasoning—grounded in the actual chart data or image features—can prevent such fabrications.
2) Using a Chart Description as a Proxy for Vision
Since smaller language models typically lack native support for image uploads, a practical workaround is to generate a textual description (caption) for your chart or diagram. You can do this manually or by leveraging specialized image captioning models such as BLIP, ViT-GPT2, or other vision-based tools. Essentially, you provide the chart image to a captioning model, get back a descriptive text, and feed that text to your smaller language model as if it were the “proxy” for the visual data.
As I uploaded the bar chart to a captioning model, it generated the below description
The bar graph displays a steady increase in population from 592 in 1995 to 831 in 2010.
Detailed description: The image is a simple black and white bar graph illustrating population growth over time. The x-axis represents the year, showing data points for 1995, 2000, 2005, and 2010. The y-axis represents population size, ranging from 0 to 900 in increments of 100. Each year is represented by a black vertical bar whose height corresponds to the population size for that year. The population figures are clearly labeled above each bar: 592 for 1995, 688 for 2000, 771 for 2005, and 831 for 2010. The title “Population” is prominently displayed at the top of the graph. The graph is clean and uncluttered, with clear labeling making the data readily understandable. The overall trend visually demonstrates a consistent upward trajectory in population over the 15-year period.
Then when we combine this caption with the question to prompt the model it results an accurate answer as shown below

In the demo we walked through, we fed the model a manually (or automatically) generated caption describing a bar chart. That’s essentially a stand-in for the image content, letting a smaller text-only model reason as if it had “seen” the chart.
However, if you want the model to directly process raw images, you typically need a multimodal architecture that has
Visual Encoder Backbone
- Incorporate a pretrained visual backbone (e.g., a Vision Transformer or CLIP encoder).
- During training, pass the raw image through this backbone to get dense embeddings (patch features).
Fusion with the Language Model
- Combine these visual features with text tokens in a shared Transformer or use a two-tower architecture that aligns image and text into a common space.
- For chain-of-thought tasks, the model’s decoder can reference both text embeddings and image embeddings to generate more grounded reasoning steps.
With this setup, the model truly looks at the image, rather than just reading a text caption. But since smaller models and off-the-shelf setups often lack this capability, our demo leverages the simpler approach—using a caption as a proxy—so we can still illustrate the essence of Multimodal-CoT reasoning on local or text-only LLMs.
Conclusion
Multimodal Chain-of-Thought is a powerful approach that brings small models closer to human-like reasoning by letting them “think out loud” with the help of both text and images. While high-end models can process raw images directly, even smaller models can benefit from visual context through simple caption-based workarounds. By structuring reasoning in two stages—first explaining, then answering—we can build models that are not only more accurate but also more transparent and grounded in reality. This bridges the gap between practical, lightweight AI and the rich, multimodal understanding we expect from smarter systems.
References
Zhang, Z., Zhang, A., Li, M., Zhao, H., Karypis, G. and Smola, A. (2023). Multimodal Chain-of-Thought Reasoning in Language Models. arXiv:2302.00923 [cs]. [online] Available at: https://arxiv.org/abs/2302.00923.
